
MPI for Parallel Tempering
Stat 221, Lecture 19
Roadmap
- MPI explained
- Messages and mailboxes
- Asynchronous (nonblocking) communication
- Parallel Tempering-specific elements
- Random number streams
- Intro to Equi-Energy Sampler
Something to think about

Example: homework
Model for ranking data based on rater class membership \\( Z_i \\).
$$Z_i \sim \rr{Multinom}_N \left(\vec{p}_i\right)$$
$$\begin{align} & l(B \given \{\vec{Z}_i, C_{ijk}\} ) = \rr{const} + \\ & \sum_{i=1}^I \left( \sum_{j \in J_i} \sum_{k \in K_{ij}} \left[ \vec{x}_{jk}' B - \rr{log} \sum_{l = 1}^{L_j} e^{ \vec{x}_{jl}' B} \right] \right) \cdot \vec{Z}_i \end{align}$$
What could be parallelized?
Pretend the data is big
Map-Reduce paradigm:
- Map the data by rater/rater group, calculate the likelihood contribution for each, reduce to the whole likelihood.
- Likelihood needs to be computed many times.
- What would be the speed of that?
Communication speed becomes a big issue. Could be 15x or more slower than doing locally.
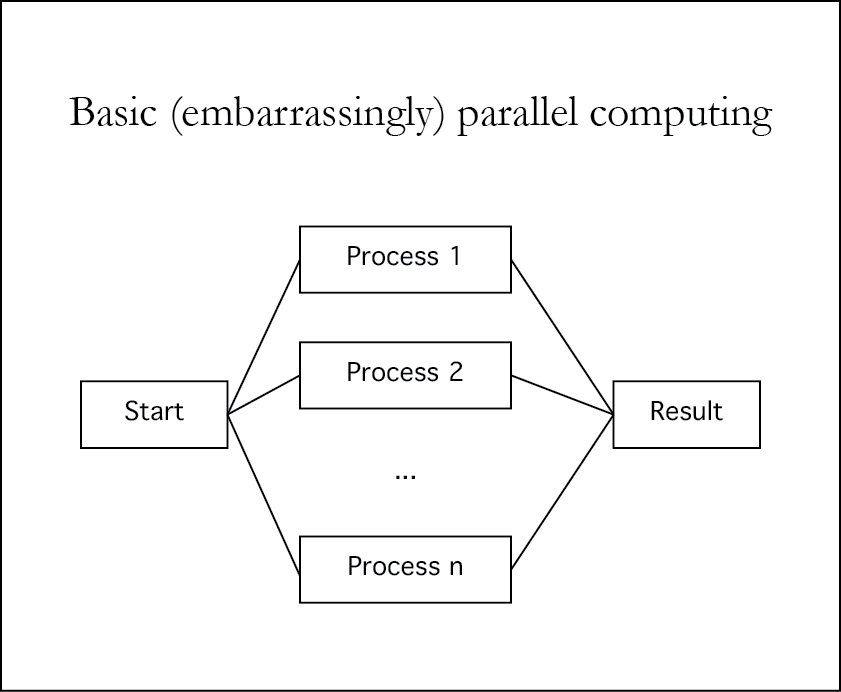
What parts of log-posterior fit this structure?
Zooming out
- To successfully parallelize in a non-GPU setting, need to be looking at a higher-level parallelism.
- We could, for example, run several chains in parallel and combine/analyze the results.
- Anything else?
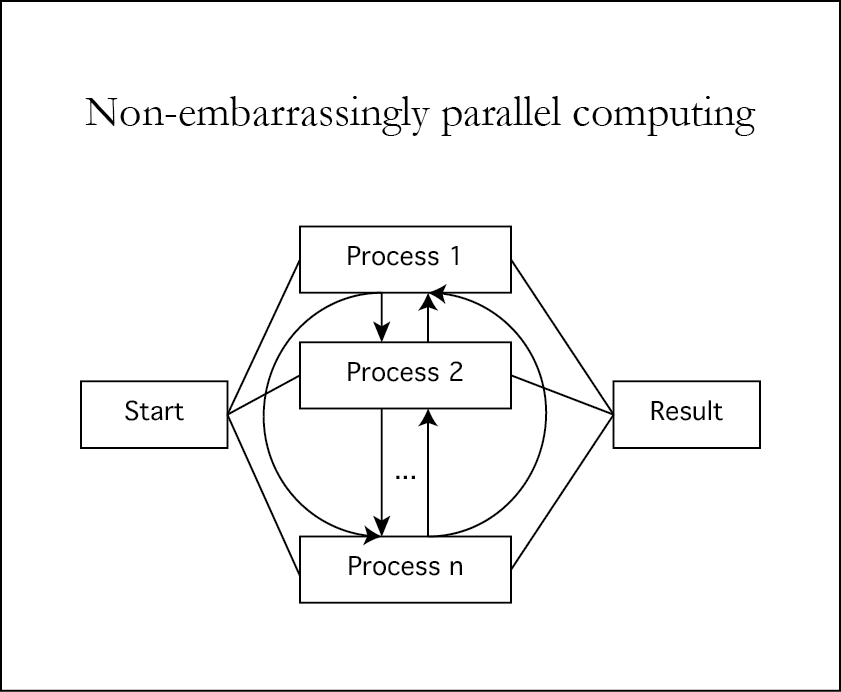
MPI
- Non-embarrassingly parallel computing is a happy alternative to slow non-GPU embarrassingly parallel computing that allows to gain performance over serial computing.
- MPI facilitates this with a flexible communication protocol.
How to make it parallel
- Run everything on one node (multicore vs no parallelization).
- Can tell worker nodes to run chains.
- Handling replica exchange communication (main thing):
- All through the master node.
- Allow maximum inter-worker communication, independent of the master.
- Pros and cons of each method?
Blocking vs non-blocking design
- Blocking design is when your parallel computing system sits idle waiting for something to occur.
- Non-blocking design is when we minimize unnecessary wait times so that the nodes do what they are supposed to do (compute) and don't sit idle.
Non-blocking design
- Want to minimize inter-node communication
- Running identical random number streams on workers.
- Communicate directly with another worker and not through master.
Getting started with MPI
- It can work using cores of your personal computer (fast communication).
- It can work on your cloud computing cluster (Rmpi on Odyssey).
- Working with MPI is about understanding asynchronous message passing between worker nodes.
Starting MPI
- Install MPI first (directions for Mac users).
library(Rmpi)
master.initializeWorkers <- function (mpistt, lgr = NULL)
{
## fix the R exit function
master.fixLast()
## start MPI workers
mpi.spawn.Rslaves(nslaves = mpistt$nworkers)
## all set
invisible(0)
}
master.initializeWorkers()Now that we have workers ready
- Time to think what they should do.
- Go back to the blackboard:
In the homework example, let
$$\rr{log}\vec{a}_i = \sum_{j \in J_i} \sum_{k \in K_{ij}} \left[ \vec{x}_{jk}' B - \rr{log} \sum_{l = 1}^{L_j} e^{ \vec{x}_{jl}' B} \right]$$
Need to sample from posterior
With a prior on \\( Z_i \\):
$$Z_i \sim \rr{Multinom}_N \left(\vec{p}_i\right)$$
$$\begin{align} \rr{log}p(B, Z \given C_{ijk} ) = & \rr{const} + \\ & \sum_{i=1}^I \left( \rr{log} \vec{p}_i + \rr{log}\vec{a}_i\right) \cdot \vec{Z}_i \end{align}$$
Definitions for Parallel Tempering
Define \\( \theta = \{B, Z \} \\), and then, conveniently, \\( E(\theta) = - \rr{log} p(B, Z \given \rr{data}) \\), and
$$\Pi (X) = \prod_{i=1}^N {e^{- \beta_i E(\theta_i)} \over D(T_i)}$$
with \\( \beta_i = {1 \over T_i }\\) and \\( D(T_i) = \int e^{- \beta_i E(x_i)} dx_i\\).
\\( T_i \\)'s are temperatures for parallel chains.
The goal
- We'd like to simulate from \\( p(\theta \given \rr{data}) \\).
- \\( \theta_i \\) are distinct copies of \\( \theta \\) running in parallel chains (replicas).
- PT will attempt to swap replicas from time to time according to acceptance probability:
$$\begin{align} &P_{\rr{replica}} (\theta_i \leftrightarrow \theta_{i+1}) = \\ & = \rr{min} \left( 1, e^{(\beta_i - \beta_{i+1})(E(\theta_i) - E(\theta_{i+1}))}\right)\end{align}$$
Note: replica exchange probability is symmetric.
Workers need to know their objects
## broadcast require/library command for all needed packages
mpi.bcast.cmd(cmd = library('MCMCpack'), rank = 0,
nonblock = FALSE)
mpi.bcast.cmd(cmd = library('rstream'), rank = 0,
nonblock = FALSE)
mpi.bcast.cmd(cmd = library('combinat'), rank = 0,
nonblock = FALSE)
## broadcast all needed functions (those whose names start
## with lpl, worker, or mpi)
funcNames <- ls(envir = .GlobalEnv)
lplfuns <- funcNames[grep("lpl|worker|mpi", funcNames)]
for (fun in lplfuns) {
mpi.bcast.NamedObj2slave(obj = eval(as.name(fun)), nam = fun)
}We are literally populating the little R sessions running on workers.
Worker random number streams
master.setupRstreams <- function (mpistt, base, lgr = NULL)
{
## NOTE : this creates two global variables in each worker:
## stream -- a variable with all random number generators
## rns -- a list with all generated random number streams
streams <- sapply(1:mpistt$nworkers, function (ii)
{
master.makePackedRstreams(nworkers = mpistt$nworkers,
base = base,
seed = mpistt$seed,
lgr = lgr)
}, simplify = FALSE)
## send random streams to workers
for (ii in 1:mpistt$nworkers) {
mpi.send.Robj(obj = streams[[ii]], dest = ii, tag = 10)
}
## broadcast all workers to receive their streams
## broadcast all workers to generate random number streams
## and store them in the rns object (to be much used later)
mpi.bcast.cmd({
stream <- mpi.recv.Robj(source = mpi.any.source(),
tag = mpi.any.tag())
rns <- worker.generateRstreams(nn = stt$niter,
stream = stream, lgr = lgr)
})
invisible(0)
}PT random number streams

- For this, need to be able to initialize random number streams at the same value and send them to workers.
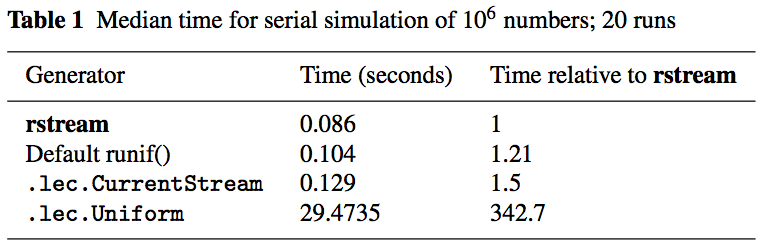
Making rstreams
## rstream is faster than other libraries*
library(rstream)
dummy <- new("rstream.mrg32k3a", seed = 1:6)
rstream.sample(dummy, 1)For details on the rstream library, see this paper.
How it all works
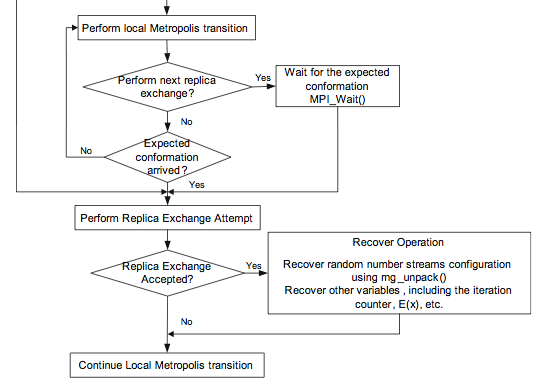
taken from the reference paper.
This looks confusing
- The formalism makes it look more complicated.
- It's easier to tell a story of how workers should behave.
Use message passing to communicate between workers.
- mpi_isend
- mpi_irecv
- mpi_wait
- ...
- Reference: Rmpi manual
How mailboxes work
- Seidning functions: mpi_send/mpi_isend (and variations)
- Receiving functions: mpi_recv/mpi_irecv
- Check mailbox: mpi_testany
- Message waiting: mpi_wait
Example
Worker 1
for (el in elements) {
mpi.isend(el, type = 2, dest = 2, tag = 1)
}
mpi.isend(0, type = 2, dest = 2, tag = 2)Worker 2
done <- FALSE
while (!done) {
x <- 0
mpi.irecv(x, type = 2, source = mpi.any.source(),
tag = mpi.any.tag())
mpi.wait()
messageinfo <- mpi.get.sourcetag()
workerid <- messageinfo[1]
tag <- messageinfo[2]
if (tag == 1) print(x) else done <- TRUE
}Better async sending/receiving
## worker 1
mpi.send(1:10, type = 2, dest = 2, tag = 0)
## worker 2
x <- numeric(10)
mpi.irecv(x, type = 2, source = 1, tag = 0)
x
mpi.wait()
xCan send and async receive vectors (unlike hw5 reference code).
Very useful embarrassing functions
- mpi.i*apply* (Rmpi Map-Reduce)
- Pset5: mpi.printObj (in lib-student.R)
mpi.printObj <- function (obj, nworkers, simplify = TRUE)
{
fun <- if (simplify) mpi.iparSapply else mpi.iparLapply
fun(1:nworkers, function (ee)
{
eval(substitute(obj))
})
}Can use mpi.printObj to print objects from workers (super useful when debugging).
Go from top-down: master node
## Run the initial pre-loop commands of the algorithm - require, globals
master.initializeAlgo(mpistt = mpistt,
objs = list(datform = datform, datorig = datorig,
stt = stt),
lgr = lgr)
## Setup the random number streams on the workers -- important to call AFTER
## initializeAlgo because this uses a transferred worker function
master.setupRstreams(mpistt = mpistt, base = rsb, lgr = lgr)
## testing code
#dia <- mpi.printObj(obj = worker(), nworkers = mpistt$nworkers, simplify = FALSE)
#master.printWorkerStatuses(obj = dia, lgr = lgr)
## at this point the workers should be equipped with the needed functions and
## we should be good to go -- time to start the main loop
mpi.bcast.cmd(cmd = { wres <- worker() }, rank = 0, nonblock = FALSE)
## master function
res <- master(mpistt = mpistt, lgr = lgr)
## align the possibly switched temperatures, and for the clean object (draws
## at temperature 1)
resA <- master.alignTemperatures(res = res, lgr = lgr)
clean <- resA[[which(stt$temp == 1)]]
# close slaves and exit.
mpi.close.Rslaves()Main functions are giant loops:
master <- function (mpistt, lgr = NULL)
{
nworkers <- mpistt$nworkers
closedworkers <- 0
res <- list()
ii <- 0
while (closedworkers < nworkers && ii < mpistt$maxiter) {
ii <- ii + 1
# Receive a message from a worker
message <- mpi.recv.Robj(mpi.any.source(), mpi.any.tag())
messageinfo <- mpi.get.sourcetag()
workerid <- messageinfo[1]
tag <- messageinfo[2]
if (tag == 1) {
## The worker is giving an update on the progress
say(lgr, 1, message)
} else if (tag == 2) {
## The worker is done, and the message contains the resulting
## object
say(lgr, 1, "Worker ", workerid, " is done")
res[[workerid]] <- message
closedworkers <- closedworkers + 1
}
}
res
}Need to careful with
- mpi.irecv and mpi.isend
- These functions are asynchronous!
From worker.irecvObject:
## here define a global variable for receiving buffer
recvObj <<- 2012.2012
mpi.irecv(x = recvObj, type = 2, source = recSrc,
tag = mpi.any.tag())Need to be constantly monitoring the recvObj buffer variable.
Worker irecv code
worker.irecvObject <- function (mpiReq, receiveFromSource, valueTag, lgr = NULL)
{
## receive object if there is no unprocessed object currently hanging
## around
if (mpiReq$allowReceiveObj) {
if (!mpiReq$objRecvInProgress) {
mpiReq$obj <- list()
}
## ensure to be receiving objects from a single source
if (!mpiReq$irecvActive) {
recSrc <- receiveFromSource
## here define a global variable for receiving buffer
recvObj <<- 2013.2013
mpi.irecv(x = recvObj, type = 2, source = recSrc,
tag = mpi.any.tag())
mpiReq$irecvActive <- TRUE
}
## check if the object has been received. If yes, populate obj with
## parsed values
if (mpiReq$irecvActive) {
testRecv <- mpi.testany(count = 1)
mpiReq$currentTag <- -1
if (testRecv$flag) {
mpiReq$objRecvInProgress <- TRUE
msginfo <- mpi.get.sourcetag()
src <- msginfo[1]
mpiReq$currentTag <- msginfo[2]
leninfo <- mpi.get.count(type = 2)
if (src != SELF) {
mpiReq$obj$source <- src
for (nam in names(valueTag)) {
if (valueTag[[nam]] == mpiReq$currentTag) {
temp <- recvObj + 0
mpiReq$obj[[nam]] <- worker.assign(temp)
break
}
}
}
mpiReq$irecvActive <- FALSE
}
}
}
mpiReq
}Announcements
- T-shirt comp.
- Final project - 2nd checkpoint.
Resources
- Slides nesterko.com/lectures/stat221-2012/lecture19
- Class website theory.info/harvardstat221
- Class Piazza piazza.com/class#spring2013/stat221
- Class Twitter twitter.com/harvardstat221
Final slide
- Next lecture: Equi-Energy Sampler.